easy-fs 文件系统实现
本节将会正式讲解 easy-fs 这个简易的文件系统.
出于解耦合考虑,文件系统 easy-fs 被分离出来,分成两个不同的 crate :
easy-fs是简易文件系统的本体;easy-fs-fuse是将用户程序user打包为.img格式 文件系统镜像的程序.
easy-fs 以层次化思路设计,自下而上可以分成五个层次:
- 磁盘块设备接口层:以块为单位对磁盘块设备进行读写的 trait 接口
- 块缓存层:在内存中缓存磁盘块的数据,避免频繁读写磁盘
- 磁盘数据结构层:磁盘上的超级块、位图、索引节点、数据块、目录项等核心数据结构和相关处理
- 磁盘块管理器层:合并了上述核心数据结构和磁盘布局所形成的磁盘文件系统数据结构
- 索引节点层:管理索引节点,实现了文件创建/文件打开/文件读写等成员函数

接下来的部分我们将从下往上逐步讲解.
BlockDevice
Section titled “BlockDevice”先前提到文件系统自底向上共有五层. 最底部是块的抽象接口 BlockDevice Trait 基于 Send + Sync + Any 实现,其中 Any 是模拟动态类型的特性,你可以参看 Any in core::any 这个文档.
两个方法 read_block 和 write_block 都以 Buffer 为中介与磁盘上的块进行读写.
BlockCache
Section titled “BlockCache”往上是块 Cache , 用内存作为磁盘块的缓存以加速 IO 操作. 定义块缓存 BlockCache 如下:
块缓存 BlockCache 内含一个 512 字节的数组,即以 u8 为一个字节,长度为 BLOCK_SZ = 512 的 [u8; BLOCK_SZ]. 成员 cache 表示位于内存中的缓冲区,block_device 表示所属的块设备.
其具有方法 get_ref 和 get_mut 用于获取地址所对应内容的引用和可变引用.
用闭包 f 进一步封装分别得到 read 和 modify 方法. 此处选择的闭包类型为FnOnce.
在此之上建立一个全局的块管理器 BlockCacheManager 用以管理内存中的 BlockCache. 方法 get_block_cache 用于在队列中搜索对应块编号的磁盘块,若队列已满则使用类 FIFO 的算法将当前块载入队列中.
由于我们希望内存中只能驻留有限的磁盘块缓冲区,我们定义 BLOCK_CACHE_SIZE = 16. 从 BlockCacheManager 中获取块缓存时会检查队列的长度是否达到了 BLOCK_CACHE_SIZE,如果达到就会发生缓存替换.
此处注意区别 BLOCK_CACHE_SIZE 是块缓存队列的长度上限,而 BLOCK_SZ 则是单个 BlockCache 中 cache 的大小.
Layout
Section titled “Layout”然后是其上磁盘数据结构层. 这其中按块编号又分为五个区域:超级块、索引节点位图、索引节点区域 DiskInode、数据块位图和数据块区域 DataBlock.
这将从 block_id 为 0 的位置开始读取超级块,然后是 block_id 为 1 的 inode_bitmap,之后是 block_id 为 (1 + inode_total_blocks) as usize 的 data_bitmap.
Bitmap
Section titled “Bitmap”接下来讨论存储的方式.
每个位图 BitmapBlock 都由若干个块组成,每个 bit 代表一个索引节点或数据块的分配状态. 而 Bitmap 则作为位图的管理器记录位图区域的起始块编号的个数.
SuperBlock 存放在磁盘上编号为 0 的块起始处. 然后是位图 Bitmap,由若干个块组成,块的大小 BLOCK_BITS 也是 512 字节,对应 512 * 8 = 4096 bits. 每一个 bit 代表一个 inode/block 的分配状态.
BLOCK_BITS是一个块大小的 bits 描述,不同于BLOCK_SZ的 Bytes 表述.
Bitmap::dealloc 的 (block_pos, bits64_pos, inner_pos) 分别是,所处哪一个编号的内存块、第几组 bits64 组(组编号)、在 bits64 组中的第几 bit(组内编号).
DiskInode & DirEntry
Section titled “DiskInode & DirEntry”接着讨论索引节点和目录项.
每个文件/目录在磁盘上均以 DiskInode 进行存储. size 表示其内容的字节数.
一个块的编号用一个 u32 进行存储。索引方式分直接和间接两种,direct 直接指向数据块,indirect1 和 indirect2 分别指向一级和二级索引块. 一级索引块中的每个 u32 指向一个数据块,而二级索引块的每个 u32 指向一个不同的一级索引块。一级索引块和二级索引块都位于数据块区域中.
块的编号用一个 u32 (4 Bytes) 存储,一个索引块最多索引 512 Bytes / 4 Bytes = 128 个数据块. DataBlock 大小为 512 字节,定义为字节数组 [u8; BLOCK_SZ].
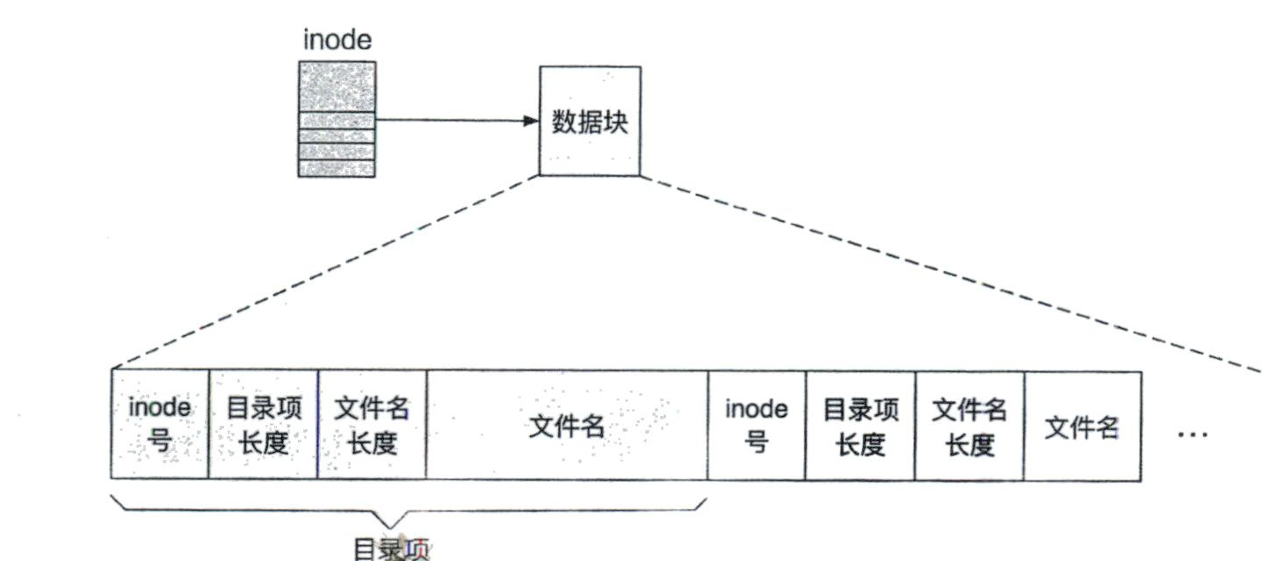
以上是索引节点. 目录对应的目录项为一个二元组 DirEntry. 目录项长 32 Bytes,每个数据块可以存 16 个目录项.
EasyFileSystem
Section titled “EasyFileSystem”为了实现磁盘数据结构的整合,将所有的数据结构存储在内存上,实现磁盘块管理器 EasyFileSystem 于 efs.rs 中. 包含设备指针 block_device,两个位图和对应起始编号.
EasyFileSystem 可以由位图上的 bit 编号得知 inode 块 (get_disk_inode_pos) 和 数据块 (get_data_block_id) 在磁盘上的实际位置,同时实现了以及 inode 和 数据块的分配与回收. EasyFileSystem::open 用于在装载了 easy-fs 镜像的块设备上打开 easy-fs,实际上就是把块编号为 0 的超级块读入.
EasyFileSystem 是一个扁平化的文件系统,在目录树上仅有一层目录,即作为根节点的根目录. 所有的文件都在根目录下.
VFS (Inode)
Section titled “VFS (Inode)”以上均为磁盘布局的处理,作为文件系统的暴露接口,最顶层的索引节点层如下. 相对于 DiskInode 放在磁盘中的固定位置,Inode作为内存中记录文件索引信息的具体数据结构. 根据其成员不难看出 Inode 是基于 EasyFileSystem 之上的实现. vfs 是为了让不同文件系统在同一个操作系统运行之上进行的抽象.
其中 block_id 和 block_offset 记录该 Inode 对应的 DiskInode 于磁盘的具体位置. 差别在于 DiskInode 放在磁盘块中比较固定的位置,而 Inode 是放在内存中用以记录文件索引节点信息的数据结构.
尽管一个文件的所有数据块在物理上是分散的,而用户一般把文件看作是一个连续的二进制 (逻辑上的).那么这一层做的事情就显而易见了:向上层屏蔽物理视角,提供喜闻乐见的逻辑视角.
Inode (index node) 也即我们实现的 DiskInode,记录了一个文件所对应的所有存储块号,而为了实现文件名与文件具体存储位置的解耦,用目录记录文件名到 inode 的映射实现解耦. 目录是一种特殊类型的文件,记录了文件名到 inode 号的映射,而因为目录本身也是文件,就可以递归地组织文件系统中的文件. 常规文件保存用户数据,而目录中保存的就是目录项 DirEntry,每个目录项代表一条文件信息记录文件名到 inode 的映射.
理解了逻辑视角后,剩下的都是方法的具体实现.
find以find_inode_id为底层实现,遍历(根)目录项下的目录项磁盘块,结果存入临时的目录项缓冲dirent中,判断名字是否相等以确定是否找到. 注意,所有暴露给文件系统的使用者的操作,全程均需持有 EasyFileSystem 的互斥锁.
ls 获取目录下所有文件的文件名. clear 调用 dealloc_data 用于清空文件. read_at 和 write_at 调用 DiskInode 的各自方法,也是以缓冲区作为中介. append_dirent 即建立文件名到 inode 的映射关系,比较常用.
先前讨论的都是 easy-fs. 然后我们就可以使用 EasyFileSystem 选择性地将 ELF 应用程序文件加载进内存,这就是 easy-fs-fuse 的功能.
FileSystem in Kernel (os/fs)
Section titled “FileSystem in Kernel (os/fs)”实现了文件系统后就要在内核中实现对接 easy-fs 的各种结构,自下而上分为块设备驱动、easy-fs 层、内核索引节点层、文件描述符层和系统调用层.
块设备驱动对接的是 Qemu, 使用 VirtIO 总线并对其 MMIO 区间进行配置. 在drivers 模块下.
easy-fs 层接受一个块设备 BlockDevice 并在其上打开文件系统 EasyFileSystem.
内核索引节点层将 easy-fs 中的 Inode 封装成 OSInode. 在 fs 模块下. OSInode 表示进程中一个被打开的常规文件或目录,描述了读写特性,又支持互斥访问和内部可变性. offset 是读写过程中的辅助偏移量.
文件描述符层就是将 File Trait 赋给 OSInode. 遍历 UserBuffer 中的缓冲区片段再调用 Inode 的 read/write_at 接口. 并且在进程 TaskControlBlockInner 中实现了文件描述符表 fd_table.
然后就是各系统调用 syscall 了,全局例化一个 ROOT_INODE 并修改相关的 syscall.